TL-B 语言
TL-B(类型语言 - 二进制)用于描述类型系统、构造函数和现有功能。例如,我们可以使用 TL-B 方案构建与 TON 区块链关联的二进制结构。特殊的 TL-B 解析器可以读取方案,将二进制数据反序列化为不同的对象。TL-B 描述了 Cell 对象的数据方案。如果您不熟悉 Cells,请阅读 Cell & Bag of Cells(BOC) 文章。
概述
我们将任何一组 TL-B 构造称为 TL-B 文档。一个 TL-B 文档通常包括类型的声明(即它们的构造函数)和功能组合子。每个组合子的声明都以分号 (;) 结尾。
这是一个可能的组合子声明示例:
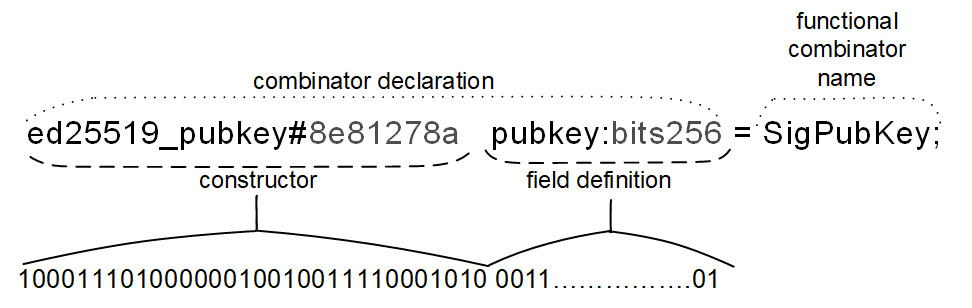
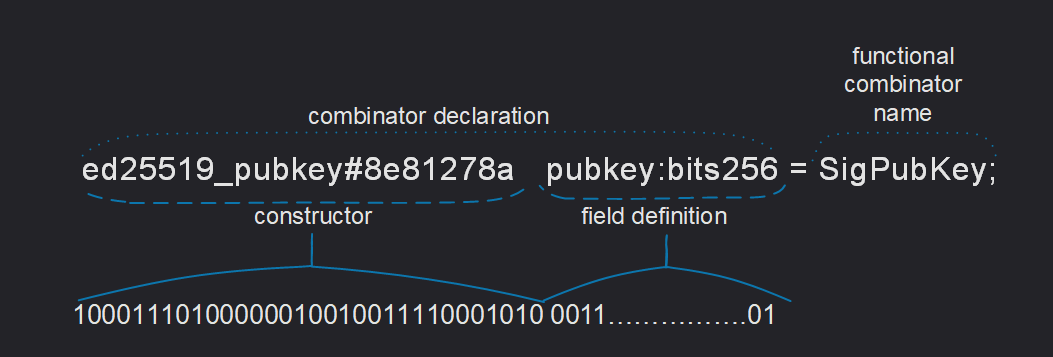
构造函数
每个等式的左侧描述了定义或序列化右侧指示类型的值的方式。这样的描述以构造函数的名称开始。

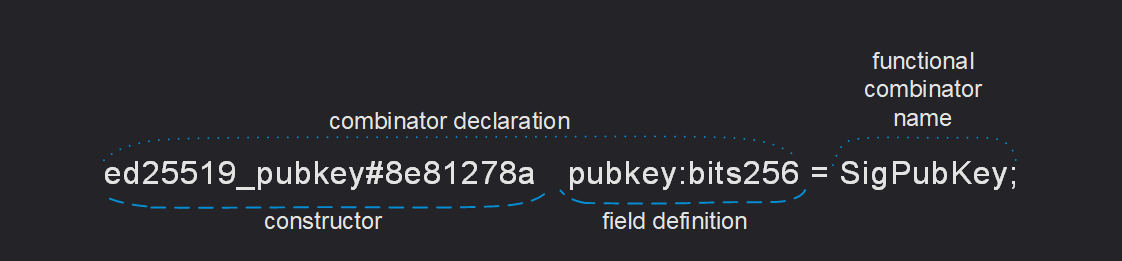
构造函数用于指定组合器的类型,包括在序列化时的状态。例如,当你想在向 TON 智能合约查询时指定一个 op(操作码)的时候,也可以使用构造函数。
// ....
transfer#5fcc3d14 <...> = InternalMsgBody;
// ....
- 构造函数名称:
transfer - 构造函数前缀代码:
#5fcc3d14
注意,每个构造函数名称后面紧跟一个可选的构造函数标签,例如 #_ 或 $10,它描述了用于编码(序列化)所讨论的构造函数的位串(bitstring)。
message#3f5476ca value:# = CoolMessage;
bool_true$0 = Bool;
bool_false$1 = Bool;
每个等式的左侧描述了定义或序列化右侧指示类型的值的方式。这样的描述以构造函数的名称开始,如 message 或 bool_true,紧接着是一个可选的构造函数标签,例如 #3f5476ca 或 $0,它描述了用于编码(序列化)所讨论的构造函数的位。
| 构造函数 | 序列化 |
|---|---|
some#3f5476ca | 从十六进制值序列化为 32 位 uint |
some#5fe | 从十六进制值序列化为 12 位 uint |
some$0101 | 序列化 0101 原始位 |
some 或 some# | 序列化 crc32(equation) \| 0x80000000 |
some#_ 或 some$_ 或 _ | 不进行序列化 |
构造函数名称(此示例中的 some)在代码生成中用作变量。例如:
bool_true$1 = Bool;
bool_false$0 = Bool;
类型 Bool 有两个标签 0 和 1。代码生成伪代码可能看起来像:
class Bool:
tags = [1, 0]
tags_names = ['bool_true', 'bool_false']
如果你不想为当前构造函数定义任何名称,只需传递 _,例如 _ a:(## 32) = 32Int;
构造函数标签可以用二进制(在美元符号后)或十六进制表示法(在井号后)给出。如果未明确提供标签,则 TL-B 解析器必须通过用 CRC32 算法散列定义此构造函数的“等式”文本,并带有 | 0x80000000 来计算默认的 32 位构造函数标签。因此,必须通过 #_ 或 $_ 明确提供空标签。
此标签将用于在反序列化过程中猜测当前位串的类型。例如,我们有 1 位位串 0,如果我们告诉 TLB 将此位串解析为 Bool 类型,它将被解析为 Bool.bool_false。
假设我们有更复杂的示例:
tag_a$10 val:(## 32) = A;
tag_b$00 val(## 64) = A;
如果我们在 TLB 类型 A 中解析 1000000000000000000000000000000001(1 和 32 个零和 1)- 首先我们需要获取前两位来定义标签。在此示例中,前两位 10 代表 tag_a。所以现在我们知道接下来的 32 位是 val 变量,在我们的示例中是 1。一些“解析”的伪代码变量可能看起来像:
A.tag = 'tag_a'
A.tag_bits = '10'
A.val = 1
所有构造函数名称必须是不同的,并且同一类型的构造函数标签必须构成一个前缀码(否则反序列化将不是唯一的);即,同一类型中的任何标签都不能是任何其他标签的前缀。
每种类型的构造函数最大数量:64
标签的最大位数:63
example_a$10 = A;
example_b$01 = A;
example_c$11 = A;
example_d$00 = A;
代码生成伪代码可能看起来像:
class A:
tags = [2, 1, 3, 0]
tags_names = ['example_a', 'example_b', 'example_c', 'example_d']
example_a#0 = A;
example_b#1 = A;
example_c#f = A;
代码生成伪代码可能看起来像:
class A:
tags = [0, 1, 15]
tags_names = ['example_a', 'example_b', 'example_c']
如果使用 hex 标签,请记住,它将以每个十六进制符号 4 位进行序列化。最大值是 63 位无符号整数。这意味着:
a#32 a:(## 32) = AMultiTagInt;
b#1111 a:(## 32) = AMultiTagInt;
c#5FE a:(## 32) = AMultiTagInt;
d#3F5476CA a:(## 32) = AMultiTagInt;
| 构造函数 | 序列化 |
|---|---|
a#32 | 从十六进制值序列化为 8 位 uint |
b#1111 | 从十六进制值序列化为 16 位 uint |
c#5FE | 从十六进制值序列化为 12 位 uint |
d#3F5476CA | 从十六进制值序列化为 32 位 uint |
十六进制值允许使用大写和小写。
关于十六进制标签的更多信息
除了经典的十六进制标签定义外,十六进制数字后面可以跟一个下划线字符。这意味着标签等于指定的十六进制数字,但没有最低有效位。例如,有一个方案:
vm_stk_int#0201_ value:int257 = VmStackValue;
实际上,标签并不等于 0x0201。为了计算它,我们需要从 0x0201 的二进制表示中删除 LSb:
0000001000000001 -> 000000100000000
因此,标签等于 15 位二进制数 0b000000100000000。
字段定义
构造函数及其可选标签后面跟着字段定义。每个字段定义的形式为 ident:type-expr,其中 ident 是字段名称的标识符(匿名字段用下划线替代),type-expr 是字段的类型。这里提供的类型是类型表达式,可能包括简单类型、带有适当参数的参数化类型或复杂表达式。
简单类型
_ a:# = Type;- 这里Type.a是 32 位整数_ a:(## 64) = Type;- 这里Type.a是 64 位整数_ a:Owner = NFT;- 这里NFT.a是Owner类型_ a:^Owner = NFT;- 这里NFT.a是指向Owner类型的cell引用,意味着Owner存储在下一个cell引用中。
匿名字段
_ _:# = A;- 第一个字段是匿名的 32 位整数
通过引用扩展cell
_ a:(##32) ^[ b:(##32) c:(## 32) d:(## 32)] = A;
- 如果出于某种原因我们想将一些字段分离到另一个cell,我们可以使用
^[ ... ]语法。 在这个示例中,A.a/A.b/A.c/A.d是 32 位无符号整数,但A.a存储在第一个cell中, 而A.b/A.c/A.d存储在下一个cell(1 个引用)中。
_ ^[ a:(## 32) ^[ b:(## 32) ^[ c:(## 32) ] ] ] = A;
- 链式引用也是允许的。在这个示例中,每个变量(
a、b、c)都存储在分离的cell中。
参数化类型
假设我们有 IntWithObj 类型:
_ {X:Type} a:# b:X = IntWithObj X;
现在我们可以在其他类型中使用它:
_ a:(IntWithObj uint32) = IntWithUint32;
复杂表达式
条件字段(仅适用于
Nat)(E?T表示如果表达式E为真,则字段类型为T)_ a:(## 1) b:a?(## 32) = Example;在
Example类型中,变量b仅在a为1时序列化。元组创建的乘法表达式(
x * T表示创建类型为T的长度为x的元组):a$_ a:(## 32) = A;
b$_ b:(2 * A) = B;_ (## 1) = Bit;
_ 2bits:(2 * Bit) = 2Bits;位选择(仅适用于
Nat)(E . B表示获取NatE的位B)_ a:(## 2) b:(a . 1)?(## 32) = Example;在
Example类型中,变量b仅在a的第二个位是1时序列化。其他
Nat运算符也允许(查看允许的约束)
注意:您可以组合几种复杂表达式:
_ a:(## 1) b:(## 1) c:(## 2) d:(a?(b?((c . 1)?(## 64)))) = A;
内置类型
#-Nat32 位无符号整数## x-Nat有x位#< x-Nat小于x位无符号整数,以lenBits(x - 1)位存储,最多 31 位#<= x-Nat小于等于x位无符号整数,以lenBits(x)位存储,最多 32 位Any/Cell- cell剩余的位数和引用Int- 257 位UInt- 256 位Bits- 1023 位uint1-uint256- 1 - 256 位int1-int257- 1 - 257 位bits1-bits1023- 1 - 1023 位uint X/int X/bits X- 与uintX相同,但您可以在这些类型中使用参数化的X
约束
_ flags:(## 10) { flags <= 100 } = Flag;
Nat 字段允许在约束中使用。在这个示例中,{ flags <= 100 } 约束意味着 flags 变量小于等于 100。
允许的约束:E | E = E | E <= E | E < E | E >= E | E > E | E + E | E * E | E ? E
隐式字段
一些字段可能是隐式的。它们的定义被花括号({、})包围,表示该字段实际上并不存在于序列化中,而是必须根据其他数据(通常是正在序列化的类型的参数)推断其值。示例:
nothing$0 {X:Type} = Maybe X;
just$1 {X:Type} value:X = Maybe X;
_ {x:#} a:(## 32) { ~x = a + 1 } = Example;
参数化类型
变量 — 即先前定义的字段的(标识符)类型 #(自然数)或 Type(类型的类型) — 可用作参数化类型的参数。序列化过程递归地根据其类型序列化每个字段,而一个值的序列化最终由表示构造器(即构造器标签)和字段值的位的串联构成。
自然数(Nat)
_ {x:#} my_val:(## x) = A x;
意味着 A 由 x Nat 参数化。在反序列化过程中,我们将获取 x 位无符号整数。例如:
_ value:(A 32) = My32UintValue;
意味着在 My32UintValue 类型的反序列化过程中,我们将获取 32 位无符号整数(因为 32 参数应用于 A 类型)。
类型
_ {X:Type} my_val:(## 32) next_val:X = A X;
意味着 A 由 X 类型参数化。在反序列化过程中,我们将获取 32 位无符号整数,然后解析类型 X 的 bits&refs。
这种参数化类型的使用示例如下:
_ bit:(## 1) = Bit;
_ 32intwbit:(A Bit) = 32IntWithBit;
在这个示例中,我们将类型 Bit 作为参数传递给 A。
如果您不想定义类型,但想按照这个方案进行反序列化,可以使用 Any 关键词:
_ my_val:(A Any) = Example;
意味着如果我们反序列化 Example 类型,我们将获取 32 位整数,然后将cell的剩余部分(bits&refs)传递给 my_val。
您可以创建带有多个参数的复杂类型:
_ {X:Type} {Y:Type} my_val:(## 32) next_val:X next_next_val:Y = A X Y;
_ bit:(## 1) = Bit;
_ a_with_two_bits:(A Bit Bit) = AWithTwoBits;
您也可以对此类参数化类型进行部分应用:
_ {X:Type} {Y:Type} v1:X v2:Y = A X Y;
_ bit:(## 1) = Bit;
_ {X:Type} bits:(A Bit X) = BitA X;
甚至可以对参数化类型本身进行参数化:
_ {X:Type} v1:X = A X;
_ {X:Type} d1:X = B X;
_ {X:Type} bits:(A (B X)) = AB X;
在参数化类型中使用 NAT 字段
您可以像参数那样使用先前定义的字段。序列化将在运行时确定。
一个简单的示例:
_ a:(## 8) b:(## a) = A;
这意味着我们在 a 字段内存储了 b 字段的大小。因此,当我们想序列化类型 A 时,需要加载 a 字段的 8 位无符号整数,然后使用这个数字来确定 b 字段的大小。
这种策略也适用于参数化类型:
_ {input:#} c:(## input) = B input;
_ a:(## 8) c_in_b:(B a) = A;
在参数化类型中使用表达式
_ {x:#} value:(## x) = Example (x * 2);
_ _:(Example 4) = 2BitInteger;
在这个示例中,Example.value 类型在运行时确定。
在 2BitInteger 定义中,我们设置了 Example 4 类型。要确定这个类型,我们使用 Example (x * 2) 定义,并根据公式计算 x(y = 2,z = 4):
static inline bool mul_r1(int& x, int y, int z) {
return y && !(z % y) && (x = z / y) >= 0;
}
我们还可以使用加法运算符:
_ {x:#} value:(## x) = Example
Sum (x + 3);
_ _:(ExampleSum 4) = 1BitInteger;
在 1BitInteger 定义中,我们设置了 ExampleSum 4 类型。要确定这个类型,我们使用 ExampleSum (x + 3) 定义,并根据公式计算 x(y = 3,z = 4):
static inline bool add_r1(int& x, int y, int z) {
return z >= y && (x = z - y) >= 0;
}
取反运算符(~)
一些“变量”的出现(即已定义的字段)前面加上波浪号(~)。这表明该变量的出现与默认行为相反:在等式的左侧,它意味着该变量将基于此出现推断(计算),而不是替代其先前计算的值;在右侧相反,它意味着该变量不会从正在序列化的类型中推断出来,而是将在反序列化过程中计算。换句话说,波浪号将“输入参数”转换为“输出参数”,反之亦然。
取反运算符的一个简单示例是基于另一个变量定义新变量:
_ a:(## 32) { b:# } { ~b = a + 100 } = B_Calc_Example;
定义后,您可以将新变量用于传递给 Nat 类型:
_ a:(## 8) { b:# } { ~b = a + 10 }
example_dynamic_var:(## b) = B_Calc_Example;
example_dynamic_var 的大小将在运行时计算,当我们加载 a 变量并使用它的值来确定 example_dynamic_var 的大小。
或者传递给其他类型:
_ {X:Type} a:^X = PutToRef X;
_ a:(## 32) { b:# } { ~b = a + 100 }
my_ref: (PutToRef b) = B_Calc_Example;
您还可以在加法或乘法复杂表达式中使用带有取反运算符的变量定义:
_ a:(## 32) { b:# } { ~b + 100 = a } = B_Calc_Example;
_ a:(## 32) { b:# } { ~b * 5 = a } = B_Calc_Example;
在类型定义中使用取反运算符(~)
_ {m:#} n:(## m) = Define ~n m;
_ {n_from_define:#} defined_val:(Define ~n_from_define 8) real_value:(## n_from_define) = Example;
假设我们有一个类 Define ~n m,它接受 m 并从 m 位无符号整数中加载 n。
在 Example 类型中,我们将 Define 类型计算出的变量存储到 n_from_define 中,我们也知道它是 8 位无符号整数,因为我们应用了 Define ~n_from_define 8 类型。现在我们可以在其他类型中使用 n_from_define 变量来确定序列化过程。
这种技术可以导致更复杂的类型定义(如联合体、哈希映射)。
unary_zero$0 = Unary ~0;
unary_succ$1 {n:#} x:(Unary ~n) = Unary ~(n + 1);
_ u:(Unary Any) = UnaryChain;
这个示例在 TL-B 类型 文章中有很好的解释。主要思想是 UnaryChain 将递归反序列化,直到达到 unary_zero$0(因为我们通过定义 unary_zero$0 = Unary ~0; 和 X 在运行时由 Unary ~(n + 1) 定义计算得知 Unary X 类型的最后一个元素)。
注意:x:(Unary ~n) 意味着 n 在序列化 Unary 类的过程中被定义。
特殊类型
目前,TVM允许以下cell类型:
- 普通(Ordinary)
- 裁剪分支(Prunned Branch)
- 库引用(Library Reference)
- Merkle证明(Merkle Proof)
- Merkle更新(Merkle Update)
默认情况下,所有cell都是普通类型。并且在tlb中描述的所有cell都是普通类型。
要在构造函数中允许加载特殊类型,需要在构造函数前添加!。
示例:
!merkle_update#02 {X:Type} old_hash:bits256 new_hash:bits256
old:^X new:^X = MERKLE_UPDATE X;
!merkle_proof#03 {X:Type} virtual_hash:bits256 depth:uint16 virtual_root:^X = MERKLE_PROOF X;
这种技术允许在打印结构时标记SPECIALcell的代码生成代码,也允许正确验证带有特殊cell的结构。
不检查构造函数唯一性标签的同一类型多个实例
允许仅根据类型参数创建同一类型的多个实例。在这种定义方式下,不会应用构造函数标签唯一性检查。
示例:
_ = A 1;
a$01 = A 2;
b$01 = A 3;
_ test:# = A 4;
意味着实际的反序列化标签将由A类型参数确定:
# class for type `A`
class A(TLBComplex):
class Tag(Enum):
a = 0
b = 1
cons1 = 2
cons4 = 3
cons_len = [2, 2, 0, 0]
cons_tag = [1, 1, 0, 0]
m_: int = None
def __init__(self, m: int):
self.m_ = m
def get_tag(self, cs: CellSlice) -> Optional["A.Tag"]:
tag = self.m_
if tag == 1:
return A.Tag.cons1
if tag == 2:
return A.Tag.a
if tag == 3:
return A.Tag.b
if tag == 4:
return A.Tag.cons4
return None
带有多个参数的情况也是一样的:
_ = A 1 1;
a$01 = A 2 1;
b$01 = A 3 3;
_ test:# = A 4 2;
请记住,当您添加参数化类型定义时,预定义类型定义(如我们示例中的 a 和 b)和参数化类型定义(如我们示例中的 c)之间的标签必须是唯一的:
无效示例:
a$01 = A 2 1;
b$11 = A 3 3;
c$11 {X:#} {Y:#} = A X Y;
有效示例:
a$01 = A 2 1;
b$01 = A 3 3;
c$11 {X:#} {Y:#} = A X Y;
注释
注释与C++中的相同:
/*
这是
一个注释
*/
// 这是单行注释
IDE 支持
intellij-ton 插件支持 Fift、FunC 以及 TL-B。
TL-B 语法在 TlbParser.bnf 文件中描述。
有用的资源
文档由 Disintar 团队提供。